第 27 章:Deep Research
Deep Research 把"搜一下"升级成"研究一下"——不是搜得更多,而是像专业研究员一样思考、规划、验证、整合。
27.1 "搜一下"和"研究一下"的区别
你让 AI 帮忙:
"帮我了解一下 AI Agent 在企业的落地情况。"
传统 AI 搜索的反应: 搜索 → 取前 5 条 → 拼摘要 → 返回。
Deep Research 的反应: "这个问题有点大,让我想想怎么拆..." → 技术挑战?组织挑战?成功案例?失败教训? → 先广泛搜一圈,看看大家在讨论什么 → 发现"安全性"被频繁提及,深挖一下 → 找到几个案例,但数据有冲突,交叉验证 → 整理成结构化报告,标注每个结论的来源
本质区别在哪里?
| 传统 AI 搜索 | Deep Research | |
|---|---|---|
| 检索 | 一次性 | 多轮迭代 |
| 推理 | 几乎没有 | 规划、适应、判断 |
| 验证 | 不验证 | 交叉验证、源质量评估 |
| 输出 | 片段拼接 | 结构化报告 + 引用 |
一句话总结:不是"搜得更多",而是"会思考"。

27.2 行业发展简史
从"搜索引擎"到"Deep Research",不是一步跨越,而是三年演进。
2022 年末:Answer Engine 的诞生
2022 年 8 月,Perplexity AI 成立。12 月,他们推出了 Perplexity Ask——一个"对话式答案引擎"。
创始人的洞察很简单:传统搜索引擎给你一堆链接,你得自己点进去找答案。为什么不直接给答案?
关键创新是引用。CEO Aravind Srinivas 说:"引用是连接搜索和 LLM 的最好方式。" Perplexity 用 RAG(检索增强生成)实时搜索网页,然后让 LLM 综合答案并标注来源。
就在一周前(11 月 30 日),ChatGPT 刚刚发布,但它没有联网能力——只能用训练数据回答,无法获取实时信息。Perplexity 从一开始就选择了不同的路线:搜索 + LLM。
2023 年:AI 搜索混战
2023 年初,竞争加剧:
- 1 月:微软宣布向 OpenAI 追加投资 100 亿美元(累计达 130 亿),把 GPT-4 集成到 Bing
- 3 月:Google 紧急推出 Bard(后来的 Gemini)
- 年中:Google 推出 SGE(Search Generative Experience),在搜索结果顶部加 AI 摘要
Perplexity 快速增长——2 月 200 万用户,年底日查询量从 2000 增长到 400 万,增长 1000 倍。
但这个阶段的 AI 搜索本质还是问答:用户问一句,AI 答一句。复杂问题需要用户自己拆解、多次提问、手动整合。
2024 年:从问答到搜索产品
2024 年是 AI 搜索产品化的一年:
- 7 月:OpenAI 推出 SearchGPT 原型,首次让 ChatGPT 能搜索网页
- 10 月:OpenAI 正式发布 ChatGPT Search,对标 Perplexity
- 12 月:Google 向 Gemini Advanced 用户推出 Deep Research
Google Deep Research 带来一个关键变化:用户提问后,AI 先展示"研究计划",用户确认后再执行。输出是"报告"而不是"回答"。
这意味着思路变了:
- 之前:AI 是"答题机器"——问什么答什么
- 之后:AI 是"研究助手"——帮你规划、执行、整合
Perplexity 2024 年增长 524%,估值突破 90 亿美元。
2025 年:Deep Research 元年
2025 年 2 月是产品转折点:
- 2 月 2 日:OpenAI 发布基于 o3 的 Deep Research,能自主规划研究、跨领域分析、生成专业报告
- 2 月 14 日:Perplexity 推出免费的 Deep Research,强调快速和可访问性
- 4 月:OpenAI 发布 o3 和 o4-mini,Deep Research 能力进一步提升
- 6 月:Anthropic 公开了多 Agent 研究系统的完整技术细节
到 2025 年中:
- AI 搜索流量占比从 2024 年的 0.02% 增长到 0.15%(7 倍)
- ChatGPT 日均超 10 亿次查询,周活突破 5 亿用户
- Perplexity 月查询 7.8 亿次,估值超过 140 亿美元
Deep Research 成了标配,但各家技术路线不同——这就是下一节要讲的。
27.3 两种架构路线
以下信息基于 2025 年中期的公开资料,各家产品持续迭代中。
路线一:单 Agent + 强推理(OpenAI)
用一个强大的推理模型完成整个研究流程。模型本身学会规划、搜索、回退、综合。
OpenAI 的 Deep Research 基于 o3 模型的特化版本。核心思路是端到端强化学习——在模拟的研究环境中训练模型,让它学会完整的研究流程:怎么规划多步搜索、走不通时怎么回退、根据实时信息怎么调整策略。这些能力不是写在代码里的,而是模型通过训练"学会"的。
为了支撑长时间的研究任务(可能跑 30 分钟),o3 扩展了注意力跨度,能在长推理链中保持上下文。同时支持跨模态分析——不只读文字,还能理解图片、提取 PDF 数据。虽然对外呈现为"单 Agent",内部其实有分层调度:便宜的小模型做预处理和分流,贵的大模型做核心推理,兼顾成本和效果。
2025 年 4 月推出 o4-mini 轻量版,让免费用户也能使用轻量版 Deep Research。
路线二:多 Agent 协作(Anthropic)
多个专门化的 Agent 分工合作。一个 Lead Agent 负责规划和综合,多个 Sub-agent 并行探索不同维度。
Anthropic 公开了完整的技术细节(下一节详细看),核心优势是并行加压缩。每个 Sub-agent 有独立的上下文窗口,可以专注探索一个维度,互不干扰。探索完成后,Sub-agent 不是把所有原始信息都传回来,而是压缩成关键发现——这避免了上下文爆炸。代价是 Token 消耗大约是单 Agent 的 15 倍,但换来的是 90% 以上的性能提升。
对比
| 维度 | 单 Agent(OpenAI) | 多 Agent(Anthropic) |
|---|---|---|
| 核心能力来源 | 模型推理能力 | 架构设计 |
| 上下文管理 | 靠模型长注意力 | 靠压缩和隔离 |
| 并行能力 | 有限(内部调度) | 原生支持 |
| 可解释性 | 较低(端到端) | 较高(步骤清晰) |
| 工程复杂度 | 低(单模型) | 高(多 Agent 协调) |
两种路线没有绝对优劣。OpenAI 路线依赖模型能力,Anthropic 路线依赖架构设计。实际产品中,两者往往会融合——OpenAI 内部也有多模型调度,Anthropic 的 Sub-agent 内部也跑推理循环。
27.4 Anthropic 的多 Agent 方案
来源:How we built our multi-agent research system(2025 年)
我们重点看他们的设计。
架构
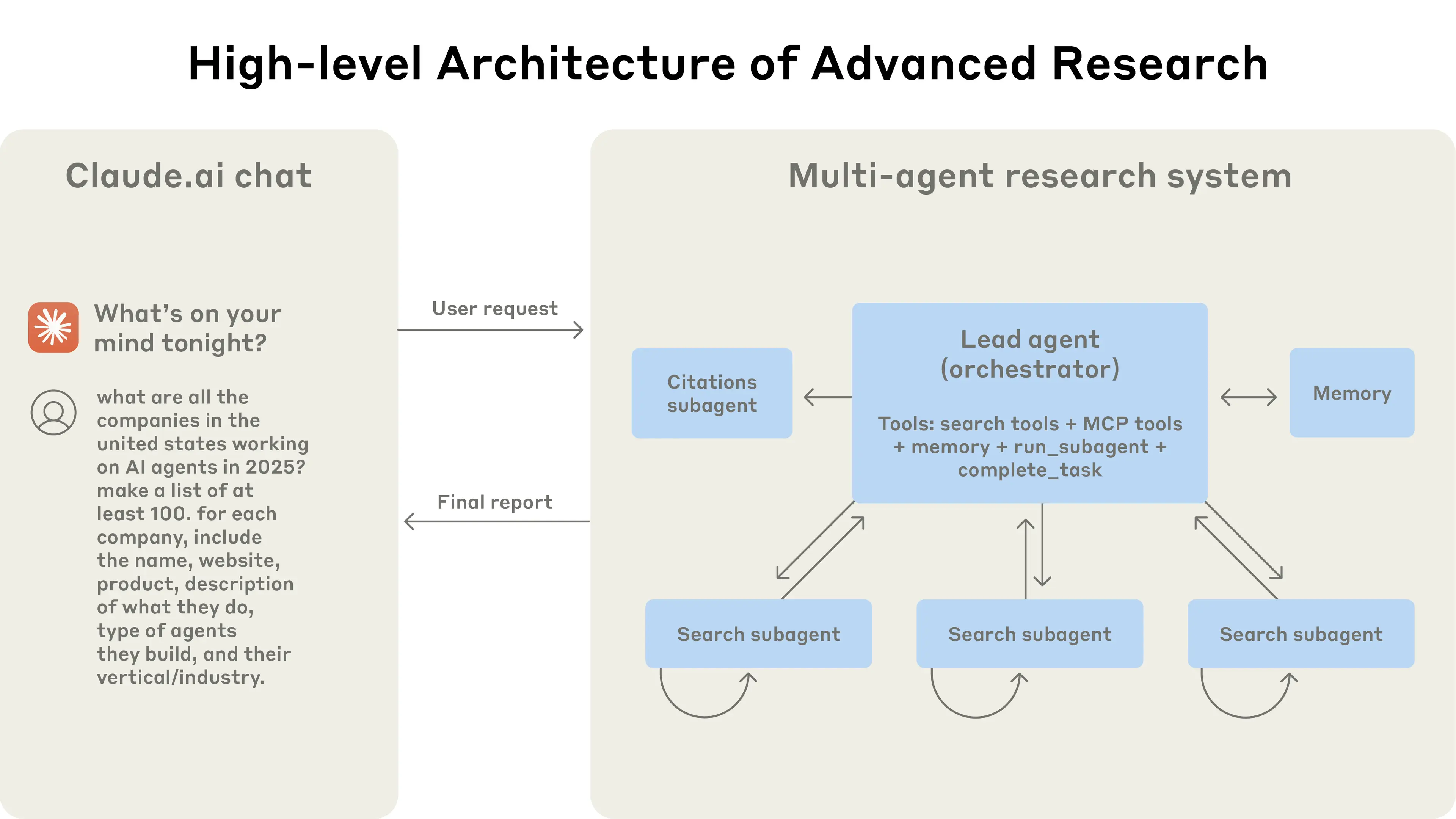
图片来源:How we built our multi-agent research system
为什么选多 Agent?
核心洞察是压缩。
每个 Sub-agent 有自己的上下文窗口,可以独立探索某个维度——比如一个负责搜技术挑战,一个负责搜成功案例,一个负责搜失败教训。
探索完后,Sub-agent 不是把所有原始信息都传给 Lead Agent,而是"压缩"——提取关键发现,丢弃细节。Lead Agent 只需要整合精华,不需要处理海量原始信息。
这样做的好处是突破了单个上下文窗口的限制。
Agent 数量怎么定?
不是越多越好。Anthropic 的经验:
| 任务复杂度 | 建议 Agent 数 |
|---|---|
| 简单事实查询 | 1 个够了 |
| 对比分析 | 2-4 个 |
| 综合调研 | 10 个以上 |
协调机制
多 Agent 最大的挑战是协调。想象一下:你派了 10 个研究员去调研同一个话题,如果没有明确分工,他们可能都去搜同样的内容,或者搜回来的信息格式各异,最后整合的人根本没法用。
Anthropic 在这里下了很大功夫。
任务分配的"契约"设计
Lead Agent 给每个 Sub-agent 的不是模糊的"去搜搜这个",而是一份清晰的"任务契约":目标是什么(不是"调研竞争对手",而是"找出 3-5 个主要竞争对手的产品定价策略")、输出格式是什么(必须是结构化的,比如"公司名 | 产品 | 价格区间")、可以用哪些工具、边界在哪里(什么不该做)。
这种契约设计让每个 Agent 的输出可预测、可组合。Lead Agent 收到的不是一堆格式各异的文本,而是可以直接整合的结构化数据。
信息传递的"压缩"问题
Sub-agent 探索一个维度可能生成几千 Token 的内容——搜索结果、访问的网页、中间推理过程。如果全部传给 Lead Agent,上下文窗口很快就爆了。
Anthropic 的做法是:Sub-agent 把完整输出存到文件系统,只传一个"摘要 + 引用"给 Lead Agent。摘要是压缩后的关键发现,引用是指向完整内容的指针。这就是"压缩"的含义——不是物理压缩,而是语义压缩:保留结论,丢弃过程。
长时间任务的错误恢复
研究任务不是秒级完成的。一个完整的 Deep Research 可能跑 10-30 分钟,期间网络可能抖动、API 可能超时、某个 Sub-agent 可能卡住。
传统做法是"出错就重来",但重跑一个 30 分钟的任务太贵了。Anthropic 的做法是检查点恢复:每完成一个关键步骤就保存状态,出错时从最近的检查点恢复。结合 AI 的适应能力——如果某个搜索路径走不通,换一个路径继续,而不是死磕。
性能数据
| 指标 | 数据 |
|---|---|
| 多 Agent vs 单 Agent 提升 | 90.2% |
| Token 消耗倍数 | 约 15× |
| Token 解释性能差异 | 80% |
最后一条很有意思:Token 使用解释了 80% 的性能差异。
换句话说,多 Agent 效果好,很大程度是因为花了更多 Token 来思考和探索。如果预算有限,可能单 Agent + 更长的推理链也能达到类似效果。
27.5 核心设计决策
不管你用什么框架实现 Deep Research,有几个设计决策避不开。
决策一:架构 × 能力来源
Deep Research 的设计空间可以用两个维度理解:
维度一:架构选择
- 单 Agent:一个模型完成全部流程,靠长程推理能力
- 多 Agent:多个专门化 Agent 分工,靠架构设计协调
维度二:能力来源
- 模型训练:通过 RL 让模型"学会"研究
- 上下文工程:通过 Prompt 设计"引导"模型研究
这两个维度组合出四种主要方案:
| 方案 | 架构 | 能力来源 | 代表 |
|---|---|---|---|
| A | 单 Agent | 端到端 RL | OpenAI Deep Research |
| B | 单 Agent | 上下文工程 | 早期 Perplexity |
| C | 多 Agent | RL + 上下文 | Anthropic 方案 |
| D | 多 Agent | 上下文工程 | Shannon、开源方案 |
OpenAI(方案 A):用端到端强化学习训练 o3 模型,让它在模拟研究环境中学会规划、搜索、回退、综合。模型本身具备研究能力,架构相对简单。
Anthropic(方案 C):多 Agent 架构 + 上下文工程的组合。Lead Agent 和 Sub-agent 的行为主要靠 Prompt 引导,但也可能结合了模型微调。
Shannon(方案 D):多 Agent 架构 + 纯上下文工程。不训练模型,完全靠架构设计和 Prompt 工程实现研究能力。这是创业公司和开源项目的主流选择——成本低、迭代快。
训练方法深入
如果你选择训练路线,2025 年主流有三种方法:
-
端到端 RL:把模型放在模拟研究环境里,给它浏览器和工具,让它完成真实任务。OpenAI 的做法。代价是需要大量模拟环境和算力。
-
RLVR(可验证奖励的 RL):用可验证的信号作为奖励——比如用代码执行验证答案对不对。好处是奖励客观、可扩展。
-
SFT + 多阶段 RL:先用监督学习教基础能力,再用 RL 逐步增加难度。微软 rStar2-Agent 的做法。好处是训练更稳定。
上下文工程深入
如果你选择不训练(或没资源训练),上下文工程是核心:
- 研究策略编码:把时间感知、源质量判断、引用追踪等策略写入 Prompt
- 任务契约:明确每个子任务的输入输出格式、可用工具、边界约束
- 动态上下文注入:根据任务类型注入不同的搜索策略
- ReAct 循环:Reasoning → Action → Observation 的迭代模式
多 Agent 架构天然需要上下文工程——你得告诉每个 Agent 它的角色是什么、怎么和其他 Agent 协作。
决策二:什么时候停?
搜太少,答案不全;搜太多,浪费钱。这个平衡点怎么找?
最简单的做法是固定轮数——比如规定搜 3 轮就停。好处是可控,坏处是一刀切:简单问题浪费资源,复杂问题又不够。
更智能的做法是覆盖率评估——把问题拆成多个维度,每轮搜索后评估各维度覆盖了多少,覆盖率达到阈值就停。代价是需要额外的推理调用来做评估,但换来的是"该多搜的多搜,该早停的早停"。
还有一种是让模型自己判断——但这需要专门训练,普通模型很难做好这个判断,要么过早停止,要么无限循环。
实践中,建议分而治之:简单事实查询用 2-3 轮硬限制,复杂综合调研用覆盖率评估加最多 5 轮的安全上限。
决策三:怎么验证引用?
搜索引擎返回的摘要是个"承诺"——它说这个网页包含你要的信息。但这个承诺经常不靠谱:摘要可能断章取义,URL 可能已经失效,内容可能早就更新了。
所以,必须实际访问 URL,拿到完整内容再决定能不能用。这一步会发现很多问题:404、付费墙、内容与摘要不符。虽然多了网络请求,但避免了"幻觉式引用"——报告里写着来源,用户点进去却发现对不上。
另一个关键是区分源质量。同样一条信息,官方网站说的和某个聚合站说的,可信度完全不同。报告应该优先引用高质量来源,对于只有低质量来源支撑的结论,标注"信息可能不准确"。
还有一点:当多个来源说法冲突时,不要替用户做选择。把冲突呈现出来,让用户自己判断。研究报告的价值是提供全面信息,不是替用户下结论。
决策四:怎么处理失败?
研究任务不是秒级完成的,可能跑 10-30 分钟。这期间网络可能抖动、API 可能超时、某个搜索可能返回空结果。如果每次出错都从头重来,成本太高了。
好的做法是异步任务管理加检查点恢复。每完成一个关键步骤就保存状态,出错时从最近的检查点继续,而不是重启整个任务。这需要把任务设计成可恢复的——状态要能序列化,步骤之间要解耦。
另一个原则是单步失败不影响全局。某个 URL 访问不了?跳过,继续访问其他的。某个搜索返回空结果?换个关键词再试。AI 本身有适应能力,让它在失败时调整策略,而不是死磕一条路。
27.6 质量保障机制
Deep Research 输出的是"报告",不是"聊天回复"。报告的质量标准更高——每个结论要有来源,信息要全面,不能有明显遗漏。这一节讲几个关键的质量保障机制。
引用追踪:每个结论必须可追溯
传统 AI 搜索的一个大问题是"幻觉式引用"——AI 说"根据某某报告",你点进去发现根本没有这个内容,甚至链接都是假的。
Deep Research 的做法是全程追踪:
研究过程中,每次调用搜索工具、每次访问网页,都记录下来。生成报告时,不是让 LLM 随便编一个引用,而是从记录中匹配——这个结论来自哪次搜索的哪个结果?那次搜索的原始 URL 是什么?
最终输出的报告里,每个关键结论后面都有 [1] [2] [3] 这样的引用标记,底部有完整的来源列表。用户可以点进去验证。
这看起来是小事,但它彻底改变了 AI 生成内容的可信度。
覆盖率评估:不是"搜完就算"
搜索 3 次和搜索 30 次,哪个够了?这个问题没有标准答案,取决于研究问题的复杂度。
一个简单的事实查询("OpenAI 什么时候成立的"),搜一次就够了。一个综合调研("AI Agent 在企业的落地情况"),搜 30 次可能还不够。
Deep Research 用覆盖率评估来解决这个问题。具体做法是:
- 在研究开始时,把问题拆成多个维度(比如"技术挑战"、"组织挑战"、"成功案例"、"失败教训")
- 每轮搜索后,评估每个维度覆盖了多少
- 如果某个维度还是空白或者信息太少,针对性地补充搜索
- 当所有关键维度都有足够信息时,停止
这比"固定搜 5 次"智能得多——简单问题不浪费资源,复杂问题不会遗漏。
时间感知:信息会过时
价格、团队规模、融资轮次、政策法规——这些信息几个月就可能变化。如果报告里写"Anthropic 估值 40 亿美元",但这是 2023 年的数据,现在早就翻倍了,那这个报告就是误导。
Deep Research 的时间感知体现在几个地方:
搜索时,对时间敏感的问题会自动加年份限定("Anthropic valuation 2025"而不是"Anthropic valuation")。排序时,优先最新的内容。生成报告时,明确标注时间上下文("截至 2025 年 Q2,Anthropic 估值约 150 亿美元")。
这让用户知道信息的时效性,也提醒他们某些数据可能需要更新。
多语言搜索:打破英语信息茧房
研究一家中国公司,只用英文搜索会怎样?
你能搜到的主要是:英文媒体的二手报道、公司官网的英文版(如果有的话)、一些财经数据聚合站。但你搜不到:天眼查上的工商信息、36氪上的行业分析、百度百科上的公司历史、知乎上的员工吐槽。
这些本地语言的信息往往更一手、更详细、更真实。
Deep Research 的多语言支持不是简单地"把查询翻译成多种语言",而是更智能的策略:
首先识别研究对象的"主场"——一家中国公司,主场是中文;一家日本公司,主场是日文。然后在主场语言中搜索官方信息(工商数据、官网、本地媒体),再用英文搜索全球视角的信息(国际媒体、投资机构报告)。最后整合时,优先官方语言的一手来源。
这大大提高了非英语实体研究的信息覆盖率。
27.7 Shannon 的设计选择
前面章节介绍过,Shannon 本身就是一个多智能体编排框架。Deep Research 是 Shannon 的核心应用场景之一,天然适合用多 Agent 架构实现 研究任务的规划和综合,多个 Sub-agent 并行探索不同维度。
Shannon 的 Deep Research 完全用上下文工程实现——不训练模型,靠架构设计和 Prompt 工程。这一节深入介绍几个核心设计,你会看到"不训练也能做好 Deep Research"是怎么实现的。

为什么搜索策略是核心?
Deep Research 的质量上限,很大程度取决于搜索策略的设计,而不是 LLM 本身有多强。
这是因为 LLM 有两个根本性的限制:
第一,幻觉问题。 即使是最强的模型,在没有外部信息支撑的情况下,也会"自信地编造"。问它一家公司的融资历史,它可能给你一个看起来很合理但完全错误的答案。Deep Research 的本质是用搜索来"锚定"LLM——让它基于真实信息推理,而不是凭空生成。
第二,训练数据的时效性。 模型的知识有截止日期。2025 年初训练的模型,不知道 2025 年中发生的事。对于时效性强的问题(融资、人事变动、政策法规),模型的"记忆"是靠不住的,必须通过搜索获取最新信息。
所以,搜索策略决定了 LLM 能看到什么信息,信息质量决定了最终报告质量。一个精心设计的搜索策略,能让普通模型产出高质量报告;一个粗糙的策略,即使用最强模型也会产出错漏百出的结果。
这就是为什么 Shannon 把大量工程精力放在搜索策略上——任务分类、域名发现、多语言搜索、引用过滤——这些"看不见"的工作,决定了最终用户看到的报告质量。
互联网搜索场景
Deep Research 的信息来源可以有很多种:公开互联网、企业内部知识库、专有数据库、甚至多模态内容(图片、PDF、视频)。
本文章先介绍Shannon在公开互联网搜索这个场景。原因很简单:这是最通用的需求,也是具有技术挑战的场景——你要处理的是全球范围的异构信息源,没有统一的格式、没有稳定的 API、质量参差不齐。
如果你的需求是搜索企业内部知识库,更适合的方案是 RAG(检索增强生成)系统——信息源可控、格式统一、不需要处理互联网的复杂性。如果你需要多模态分析(从财报 PDF 提取表格、从产品图片识别信息),那需要专门的多模态处理管道。
这些都是 Deep Research 的延伸方向,但不在本章讨论范围内。
搜索与验证分离:对抗"幻觉式引用"
Deep Research 最常见的错误是信任搜索摘要。
搜索引擎返回的摘要是怎么来的?它从网页中提取一段看起来相关的文字,但这段文字可能断章取义、可能过时、可能根本不是你想要的内容。如果 AI 直接拿这个摘要写进报告,用户点进去一看——根本不是那么回事。
Shannon 的做法是把搜索和验证严格分开:
搜索阶段只做一件事:拿到 URL 列表。摘要只用来初步筛选(这个链接值不值得访问),绝不直接引用。
验证阶段是真正获取信息的地方。对每个值得深入的 URL,实际发起 HTTP 请求,拿到完整的网页内容,提取正文。这一步会发现很多问题:有些 URL 已经失效(404),有些网页是付费墙,有些内容跟摘要完全不一样。
确认阶段决定哪些内容能进报告。只有验证过的、内容确实相关的、来源可信的,才能被引用。
这意味着更多的网络请求和 Token 消耗。但换来的是:报告里的每一个引用,用户点进去都能看到支持结论的原始内容。
任务类型决定搜索策略:不同问题,不同打法
"调研一家上市公司"和"Transformer 的工作原理",需要的搜索策略完全不同。前者要找工商数据、融资新闻、官网信息;后者要找论文、技术博客、教程。如果用同一套策略,要么效率很低,要么漏掉关键信息。
Shannon 在查询细化阶段做一件重要的事:识别任务类型,然后注入对应的搜索策略。
| 类型 | 示例 | 策略差异 |
|---|---|---|
| 公司调研 | "调研字节跳动" | 先发现官方域名,抓取官网关键页面,再搜工商数据源和新闻 |
| 行业分析 | "AI 芯片市场" | 找报告类内容,注重数据和横向对比,搜索多个竞争者 |
| 学术研究 | "Transformer 原理" | 优先论文和技术博客,追引用链,找被大量引用的关键文献 |
| 对比分析 | "React vs Vue" | 刻意搜索多方观点,保持中立,不能只看某一方社区的声音 |
这种"任务类型 → 搜索策略"的映射是上下文工程的核心。不是让 LLM 自己想怎么搜,而是根据任务类型直接告诉它应该怎么搜。
ReAct 循环:像人一样边搜边调整
你自己做研究的时候,是不是这样的过程?先搜一个大概的词,看看结果。发现结果太泛了,于是加几个限定词再搜。看到一个有意思的结果,顺着它提到的名词继续搜。发现某个维度信息很少,换个角度再找找。
这就是 ReAct(Reasoning + Action)循环的本质:不是一次性规划好所有搜索,而是边思考边行动,根据观察到的结果调整策略。
Shannon 让每个 Sub-agent 内部运行这样的循环:
思考:当前问题是什么?已经知道什么?还缺什么?
↓
行动:执行一次搜索或访问一个网页
↓
观察:搜索返回了什么?有没有回答问题?
↓
再思考:够了吗?下一步怎么调整?
↓
继续或停止关键的参数控制:
- 最大迭代次数:通常 2-3 轮,防止无限循环。即使问题没完全解决,也要在有限步内停下
- 最大访问页面数:一个 Sub-agent 最多访问多少网页,太少信息不够,太多浪费资源
- 子页面探索:对重要网站(比如公司官网),不只访问主页,还会访问关键子页面(/about、/products、/team)。可以用广度优先遍历,也可以让 LLM 选择最相关的子页面
覆盖率驱动停止:智能判断"够了没"
"够了没"是 Deep Research 最难回答的问题。搜太少,报告会有明显漏洞;搜太多,浪费时间和 Token。
Shannon 用覆盖率评估来解决这个问题:
- 研究开始时,把问题拆成多个维度(比如"技术挑战"、"成功案例"、"市场规模")
- 每轮搜索后,评估每个维度覆盖了多少——不是简单计数,而是语义评估
- 覆盖率达到阈值(比如 85%),停止
- 某个维度明显是空白,生成针对性子查询继续填补
- 同时有一个硬限制——最多 5 轮迭代,防止极端情况
这比"固定搜 5 次"聪明得多,也比"让 LLM 自己判断"可控得多。
引用过滤与质量分级
搜索"字节跳动",可能会搜出很多包含"字节"或"跳动"的无关结果——某个叫"字节"的小公司、某篇提到"跳动"的新闻。Shannon 实现了一个引用过滤器,用计分系统判断搜索结果是不是真的相关。
过滤逻辑是这样的:如果 URL 是官方域名(bytedance.com),直接通过,不需要其他判断。否则,看 URL 和标题中有没有出现公司名称或其变体(ByteDance、字节跳动、抖音母公司),出现就加分。最后只保留分数超过阈值的结果。
有个重要的安全机制:无论过滤多严格,至少保留一定数量的引用。这是为了防止过度过滤——如果过滤太狠,可能把所有结果都滤掉了,导致研究无法继续。
通过过滤后,还有质量分级:
一手来源优先级最高:官方网站、官方文档、SEC 申报文件。这些直接来自信息源,最可信。
专业媒体次之:TechCrunch、36氪、日经新闻。有编辑审核,质量有保证。
聚合站点最低:各种数据聚合网站、百科类网站。信息可能过时或不准确。
综合阶段优先使用高质量来源。如果只有低质量来源,会标注"信息可能不准确"。
多语言搜索的智能策略
研究非英语实体时,Shannon 不是简单地"把查询翻译成多种语言",而是更智能的策略:
识别"主场":通过公司总部、主要市场、官网语言判断实体的主场语言。字节跳动的主场是中文,Toyota 的主场是日文。
差异化搜索:主场语言搜索官方信息(工商数据、本地新闻、官网),英文搜索全球视角(国际媒体、投资机构报告)。
来源优先级:同样的信息,主场语言的官方来源优先于英文的二手报道。字节跳动的员工人数,天眼查比 TechCrunch 更可信。
27.8 发展方向
Deep Research 还在快速演进。几个值得关注的方向:
多模态理解。当前的 Deep Research 主要处理文本,但很多重要信息藏在图片、PDF、视频里——财报里的表格、产品发布会的演示、专利文档的示意图。下一代 Deep Research 需要能"看懂"这些内容,从中提取结构化数据。OpenAI 的 o3 已经开始支持图片和 PDF 分析,这个能力会逐步成为标配。
实时协作。目前的 Deep Research 是"用户提问 → AI 跑完 → 返回报告"的单向流程。但研究往往是探索性的——跑到一半发现某个方向更有价值,想调整重心;或者看到中间结果,想追问某个细节。未来的 Deep Research 应该支持用户在研究过程中介入、引导方向,而不是只能干等结果。
持续学习。每次研究都从零开始是浪费。如果你上周调研过"AI 芯片市场",这周调研"英伟达竞争格局",后者应该能复用前者的部分成果。更进一步,系统应该学习用户的偏好——你关注哪些信息源、喜欢什么样的报告结构、对哪些领域更熟悉。这需要长期记忆和个性化能力。
垂直专业化。通用的 Deep Research 能处理大多数场景,但专业领域有专业需求。学术研究需要追踪引用链、评估期刊影响因子;金融分析需要解读财报、跟踪监管公告;法律调研需要理解判例、关联法条。这些垂直场景需要专门的工具、数据源和评估标准,会催生专业化的研究 Agent。
27.9 常见误区
| 误区 | 正解 |
|---|---|
| 多搜几次就是 Deep Research | 重点是规划、适应、验证、整合 |
| 多 Agent 一定比单 Agent 好 | 多 Agent 的好处很大程度来自更多 Token |
| Token 越多越好 | 有边际递减,需要预算控制 |
| 搜到了就能用 | 要实际访问验证,标注源质量 |
| 英文搜就够了 | 非英语实体要搜本地语言源 |
27.10 本章要点
✅ 本质:会思考的研究,不是搜得更多——Plan → Search → Evaluate → Verify → Synthesize
✅ 设计空间:两个维度组合
- 架构:单 Agent vs 多 Agent
- 能力来源:模型训练 vs 上下文工程
✅ Shannon 定位:多 Agent 架构 + 纯上下文工程,不训练模型,靠架构设计和 Prompt 工程实现
✅ Shannon 核心设计:
- 搜索与验证分离,避免"幻觉式引用"
- 任务类型决定搜索策略
- ReAct 循环边搜边调整
- 覆盖率驱动停止(≥85%)
- 引用质量分级
27.11 延伸阅读
-
How we built our multi-agent research system Anthropic 工程博客,详细介绍多 Agent 架构的设计考量,理解"压缩"为什么是核心洞察。
-
Introducing deep research OpenAI 官方博客,介绍 Deep Research 的产品设计和用户场景。
-
Deep Research: A new agentic capability in Gemini Google 的 Deep Research 方案,强调"研究计划"的用户确认流程。
27.12 Shannon Lab(10 分钟上手)
必读(2 个文件)
-
workflows/strategies/research.go完整工作流编排——Step 0 到 Step 5 的全流程实现,理解 Refine → Research → Synthesize 循环,覆盖率评估和迭代控制逻辑。 -
roles/deep_research/deep_research_agent.py研究员角色定义——研究策略编码、时间感知、区域源、ReAct 循环的 Prompt 设计。
选读深挖(2 个)
-
roles/deep_research/research_refiner.py任务分类与维度拆解——看 Shannon 如何识别任务类型(公司/行业/学术/对比/探索),以及 Source Guidance 的生成逻辑。 -
roles/deep_research/domain_discovery.py+domain_prefetch.py官方域名发现与预抓取——如何找到实体的官方网站、提取结构化信息并注入后续 Agent 上下文,理解为什么一手来源比搜索引擎更可靠。
快速上手路径
1. 先读 research.go 理解全流程(10 分钟)
↓
2. 读 deep_research_agent.py 看 Prompt 设计(5 分钟)
↓
3. 挑一个感兴趣的模块深入
- 对任务分类感兴趣 → research_refiner.py
- 对信息获取感兴趣 → domain_discovery.py + domain_prefetch.py下一章预告
第 28 章:当 Agent 获得"眼睛"和"手"——Computer Use 让 AI 能操作真实界面,打开全新的能力边界。