In my previous post on AI quantitative trading, I explored the landscape — what quant trading really is, why AI has a genuine edge, and where the real barriers lie. The conclusion was clear: the mystery of quant funds isn't intellectual complexity, it's information asymmetry and engineering execution.
This post is the follow-up. Over the past few months, I've been building Dnalyaw — a full-stack quantitative trading platform that takes the ideas from that earlier post and turns them into running code. Real market data flowing in. Real orders going out. Real risk checks happening in nanoseconds.
Let me walk you through the engineering decisions, the architecture, and why I believe the approach matters more than the model.
Why Build From Scratch?
The honest answer: existing frameworks don't respect the latency hierarchy.
Most open-source quant platforms treat everything the same — Python top to bottom. That works for research. It fails spectacularly when you need sub-microsecond risk checks on every order while simultaneously running ML inference and managing a portfolio of 50+ positions across multiple markets.
The other issue is risk. When real money is on the line, you can't afford "best effort" risk management bolted on as middleware. The risk engine needs veto authority. It needs to be physically incapable of being bypassed by a rogue strategy or a misbehaving LLM agent. That requires architectural separation, not just a Python decorator.
The Polyglot Architecture: Rust + Go + Python
Dnalyaw uses three languages, each chosen for a specific latency tier. This isn't complexity for its own sake — it's matching the tool to the constraint.
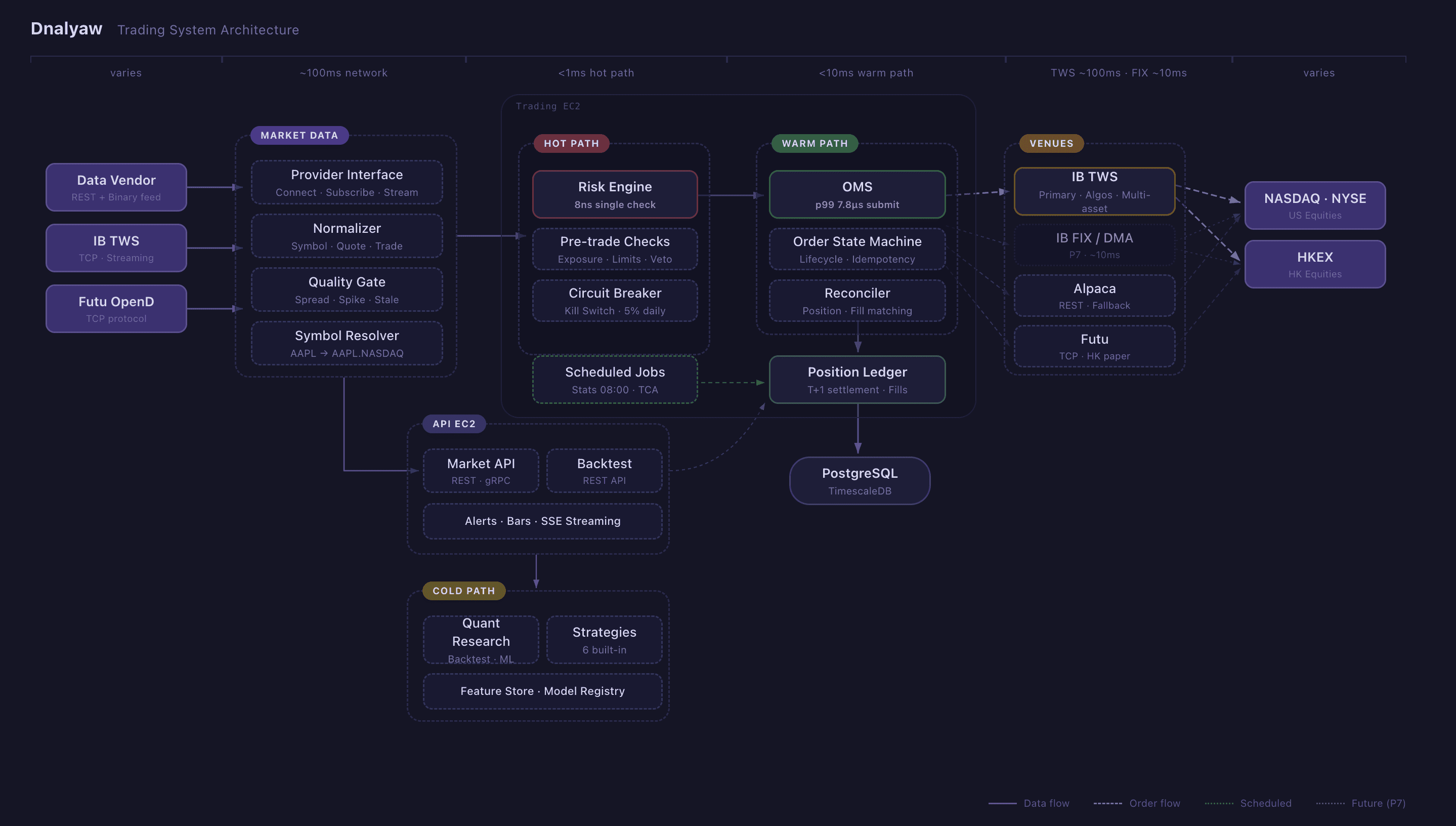
Rust: The Hot Path (<1ms)
The risk engine and execution core run in Rust. Every single order passes through pre-trade risk checks that complete in 8 nanoseconds for basic validation and 244 nanoseconds even with 50 active positions. These are Criterion.rs measurements on the actual production risk engine.
Why Rust? Memory safety without garbage collection pauses. When you're checking risk limits on every order, a 10ms GC pause in Java or Go means 10ms where orders queue up unchecked. Rust's ownership model eliminates this entirely. The risk engine has zero allocations in the hot path.
The risk engine also implements a kill switch — a circuit breaker that can flatten all positions and enter reduce-only mode within microseconds. It has a direct-wire bypass to the broker, meaning it can emergency-close positions even if the Go orchestrator is completely down.
Go: The Warm Path (<10ms)
The Order Management System, strategy orchestration, API layer, and real-time monitoring TUI all run in Go. Goroutines and channels are a natural fit for the workflow: receive market data, fan out to strategies, collect target portfolios, route through risk, manage order lifecycle.
The OMS achieves p99 order submission of 228 microseconds at 907 orders/second throughput — well within our target of <1ms. The order state machine handles the full lifecycle: new, submitted, acknowledged, partially filled, filled — with idempotency guarantees and automatic reconciliation against broker state.
Go sits in the sweet spot between Rust's raw performance and Python's ecosystem. It's fast enough that the warm path never becomes a bottleneck, while being productive enough to iterate on business logic quickly.
Python: The Cold Path (async)
Research, backtesting, ML/RL model training, and LLM integration live in Python. This is where developer velocity matters more than execution speed. Six strategies are currently implemented — from simple dual moving average crossovers to a regime-adaptive multi-factor ensemble.
Python strategies don't generate orders directly. They output target portfolio weights that flow through gRPC to the Go execution layer. This separation is critical: a bug in a Python strategy can produce bad targets, but it physically cannot bypass risk limits or send malformed orders to the broker.
The Python layer also hosts the backtest engine (wrapped in FastAPI for remote access), a feature store backed by TimescaleDB, and the bridge to our LLM orchestration platform for sentiment analysis.
Risk Management: Defense Before Offense
If I had to pick the single most important design decision in Dnalyaw, it's this: the risk engine has absolute veto authority, and it's written in a language where entire classes of bugs are impossible.
Four Risk Decisions
Every order receives one of four responses:
- APPROVE: Proceed as requested
- REJECT: Block entirely — limit breached, market closed, or concentration too high
- REDUCE: Scale down the order (e.g., you requested 100 shares but exposure limits allow only 60)
- FLATTEN: Emergency mode — close all positions, enter reduce-only
REDUCE is the interesting one. Most risk systems are binary — yes or no. But in practice, a strategy might be directionally correct while over-sizing. Reducing the order preserves the alpha signal while enforcing the risk boundary.
Hardcoded Limits (Not Configurable)
Some limits are deliberately immutable constants in Rust, not configuration:
- Max 5% notional per instrument
- Max 25% sector exposure
- 5% daily drawdown kill switch
- 1% single-trade risk (Van Tharp floor)
Why hardcode? Because at 2 AM when a position is bleeding and your brain is telling you "just override it this once," the system should say no. Configurable limits get reconfigured. Constants don't.
Position Sizing: Half-Kelly + Van Tharp
I use two complementary models simultaneously:
Half-Kelly (offense — sets the ceiling): The Kelly criterion gives mathematically optimal bet sizes for long-term compound growth. The full Kelly fraction is:
where is the win rate and is the reward/risk ratio. We use half-Kelly to account for estimation error and fat tails. This tells you the most you should bet.
Van Tharp R-Multiple (defense — sets the floor):
This ensures no single loss exceeds 1% of capital. This tells you the least protection you need.
The final position size is always the most conservative of all constraints:
Offense defines opportunity; defense defines survival.
Multi-Market Execution
Dnalyaw currently trades US equities (NASDAQ, NYSE) and Hong Kong equities (HKEX), with the architecture ready for additional markets.
Provider Abstraction
Every external integration — data feeds, brokers, exchanges — goes through a clean abstraction interface. Adding a new data provider means implementing Connect, Subscribe, and Stream. Adding a new broker means implementing SubmitOrder, CancelOrder, and ModifyOrder. The internal canonical data model normalizes everything: AAPL.NASDAQ, 0700.HKEX — same format, same pipeline.
This matters because the real world is messy. One provider sends binary-encoded market data. Another uses a TCP streaming protocol. A third uses REST. Yet another has its own protobuf-based protocol. All of this gets normalized into a single Quote struct before anything downstream sees it.
Quality Gates
Raw market data is unreliable. Spreads spike. Prices go stale. Data feeds drop. Before any market data reaches the strategy layer, it passes through quality gates that check for:
- Abnormal bid-ask spreads (likely bad tick)
- Stale timestamps (feed lag or disconnection)
- Price spikes beyond statistical norms (fat-finger trades or data errors)
A bad quote that sneaks through can trigger a cascade of wrong orders. Quality gates are cheap insurance.
From Backtest to Live: The Calibration Pipeline
This is where most quant projects fail. The backtest shows a Sharpe of 2.0, you go live, and reality delivers 0.3. The gap is always the same: unrealistic fill assumptions.
Two-Layer Backtesting
Dnalyaw runs two distinct backtest modes:
- Fast Python vectorized backtest: For rapid strategy iteration. Tests signal logic against historical data in seconds.
- Go OMS-integrated backtest: Exercises the real order state machine with a simulated venue. Catches bugs that only appear in production — partial fills, order rejections, settlement timing.
Realistic Fill Modeling
The backtest fill model incorporates:
- Bid-ask spread slippage: You always cross the spread
- Volume-based market impact: Using the Almgren-Chriss square-root impact model — your own orders move prices against you
- Fill probability for limit orders: Not every limit order fills
- Execution latency: Log-normal distribution calibrated to actual measured latencies
Shadow Trading
Before going live, strategies run in shadow mode — executing in simulation alongside real market data. The system compares shadow P&L to what live execution would have produced, tracking drift across four dimensions: daily P&L, Sharpe ratio, fill rates, and average slippage. If any metric drifts beyond threshold, it triggers investigation before the strategy graduates to live capital.
Validation Pipeline
The progression is explicit: shadow → paper trading → canary (limited capital) → live. Each stage has graduation criteria. You don't skip stages because your backtest looked good.
The AI Layer: LLMs for Alpha, RL for Execution
Here's where it gets interesting — and where I disagree with most of the "AI trading" discourse.
LLMs Should Not Predict Prices
Everyone is feeding OHLCV data into GPT and asking for buy/sell signals. This is crowded, the alpha is near zero, and it's exactly what you'd expect when thousands of developers try the same approach simultaneously.
Where LLMs actually have edge: unstructured data risk analysis. Reading 10-K filings for lawsuit risks. Detecting management tone shifts in earnings calls. Flagging accounting irregularities that break cointegration relationships. This is genuinely hard to do at scale without language models, and it's not crowded because it requires domain-specific pipelines, not API calls.
In Dnalyaw, the LLM layer integrates with Shannon — our multi-agent orchestration platform — and has strict architectural boundaries:
Production-Grade Multi-Agent Platform - Built with Rust, Go, and Python for deterministic execution, budget enforcement, and enterprise-grade observability.
What LLMs can do: Analyze sentiment, extract earnings data, propose factor hypotheses, detect risk signals in unstructured filings
What LLMs cannot do: Generate buy/sell signals, calculate position sizes, modify risk parameters, execute orders, disable stop-losses
This isn't a policy — it's architecture. The LLM outputs features that feed into deterministic quantitative systems. It never touches the order path.
RL for Trading Actions
Signal generation — alpha factors, technical indicators, LLM sentiment scores — comes from the quant research layer. The RL agent's job is different: it consumes those signals as part of its state and decides how to act on them. The pipeline formulates this as a Markov Decision Process:
- State: Market regime (VIX, trend indicators), portfolio state (leverage, drawdown, Sharpe), per-instrument features (price, volatility, RSI, sentiment scores from LLM), pairs features (spread z-score, cointegration)
- Action: Target portfolio weights — what the portfolio should look like, not individual orders
- Reward: A weighted combination that balances profit with risk discipline:
The RL agent outputs TargetPortfolios, and the execution layer figures out how to get from current positions to those targets optimally — handling order routing, partial fills, and settlement. This separation means the RL agent focuses purely on the decision: given these signals and this portfolio state, what should I hold?
We're exploring both PPO (stable for non-stationary markets) and SAC (sample-efficient when data is expensive), with rolling retraining every 30 days to handle regime changes.
TensorLogic: The Reasoning Engine Behind RL
The RL pipeline above needs more than just pattern matching — it needs to reason about market structure. This is where TensorLogic comes in.
A Python implementation of Tensor Logic - a unified programming language for AI that combines neural and symbolic reasoning through tensor equations.
TensorLogic is a framework I built based on Pedro Domingos' paper "Tensor Logic: The Language of AI". It unifies symbolic reasoning and neural learning into a single computational substrate — tensor equations. A logical rule like becomes a matrix multiplication: . Everything — logic, attention, composition — reduces to the same tensor operations.
Why does this matter for quant trading? Traditional RL agents are pure neural — they learn patterns from data but can't enforce logical constraints or explain their reasoning. Pure rule-based systems are brittle and can't adapt. TensorLogic gives us both:
Boolean mode for hard trading constraints: Market regime rules, position limits, and risk boundaries are expressed as strict logical constraints — no hallucination, no approximation. When the system says "this violates dollar neutrality," it's provably correct.
Continuous mode for learning**: Relations between instruments, sectors, and macro factors become learnable embedding matrices. The scoring function lets the model discover latent relationships — like which sector rotations predict which, or how a VIX regime shift propagates through correlated pairs — without being told these patterns exist.
The dual-mode architecture maps directly to Dnalyaw's latency hierarchy. During training, the RL agent operates in continuous mode — learning portfolio weight policies through gradient descent on the reward function. During live inference, critical constraints switch to Boolean mode — guaranteeing that no learned policy can violate risk limits, regardless of what the neural components suggest.
The most powerful capability is predicate invention via RESCAL tensor factorization. Feed TensorLogic a knowledge graph of instrument relationships, macro indicators, and historical regime labels, and it autonomously discovers latent factors — concepts like "momentum cluster" or "liquidity regime" that weren't explicitly defined. These invented predicates become first-class features for the RL state space, expanding what the agent can reason about beyond human-defined indicators.
This is fundamentally different from throwing OHLCV data at a neural network and hoping it learns something. TensorLogic provides structured, composable, explainable reasoning — and at 10-500KB model size with training in seconds, it's orders of magnitude more efficient than LLM-based approaches.
AlphaAgent: Factor Mining with LLMs
One of the more experimental pipelines: an LLM generates factor hypotheses (e.g., "companies with increasing R&D spend relative to revenue outperform over 6 months"), a backtesting validator tests them against historical data, and a decay checker uses AST similarity analysis to detect if the proposed factor is too similar to known crowded factors. If the originality score falls below 0.7, the factor is rejected before it ever reaches live trading.
This addresses the alpha decay problem head-on. In efficient markets, any factor that everyone discovers simultaneously loses its edge. The system explicitly checks for novelty.
Observability: Built In, Not Bolted On
Every component in Dnalyaw includes observability at implementation time. Not after. Not in the next sprint. In the same commit.
Three pillars:
- Structured logging with correlation IDs that trace an order from signal generation through risk check, OMS, venue submission, to fill receipt
- Metrics (OpenTelemetry → Prometheus) with latency histograms, order counters by status/venue/symbol, exposure gauges, P&L tracking
- Audit trail — an immutable PostgreSQL table capturing every state change with timestamp, actor, and full payload. Every risk decision includes a snapshot of all metrics at decision time.
For real-time operations, I built a terminal UI (TUI) using Go's bubbletea library — tabs for positions, live quotes, order book, risk dashboard, alerts, and watchlists. No web framework. Most prop trading desks use Grafana + custom terminal tools, and there's a good reason: they're fast, reliable, and don't crash when WebSocket connections drop.
What I've Learned So Far
Building Dnalyaw has reinforced several beliefs:
Build execution first, strategies last. You cannot test strategies without reliable execution. Most quant projects start with the model and bolt on execution later. This is backwards.
Backtests always lie. Not because they're broken, but because they can't model everything. Slippage, borrow costs, market impact at scale, latency — these compound. Shadow trading is the antidote.
Alpha expectations should be honest. In efficient US markets, stat-arb pairs trading has a realistic 5-10% annual return ceiling after costs. A Sharpe above 1.0 is good. A Sharpe above 2.0 is suspicious (check your assumptions). 15-20% annually is excellent. If your backtest shows 50%+, something is wrong.
The edge isn't the model — it's the execution. Renaissance's Medallion fund reportedly spends more engineering effort on execution cost optimization than on alpha generation. At any AUM, the difference between a good fill and a bad fill compounds dramatically over thousands of trades.
Risk engineering is more important than alpha. A mediocre strategy with bulletproof risk management survives to trade another day. A brilliant strategy with bad risk management eventually blows up. The asymmetry is absolute.
What's Next
Dnalyaw is actively trading in paper mode across US markets, with HK market support in testing. The immediate roadmap:
- RL training pipeline with calibrated environment simulators
- Feature store with point-in-time correctness for ML training (preventing lookahead bias)
- China A-shares expansion — 80% retail participation means dramatically higher alpha opportunity compared to institutional-dominated US markets
- TCA (Transaction Cost Analysis) integration — measuring arrival price vs. fill price on every trade to continuously calibrate execution quality
- Decision Transformer research track — return-conditioned policy generation where you specify a target Sharpe and the model generates actions to achieve it
The architecture is designed to scale from a single developer's paper trading account to a multi-strategy, multi-market operation — though I'm under no illusion about the distance between those two points.
The real test isn't the backtest. It's the next thousand live trades.
This is part of my series on AI quantitative trading. The previous post, AI Quantitative Trading: From Models to Quant Funds, covers the conceptual foundation. Follow me for updates as the system evolves.