In xianxia novels, a cultivator climbs through realms. Each step up reveals a deeper layer of reality that was always present — just invisible from below. Neural networks work the same way. Below is a four-realm reading of what deep learning actually is. Each realm is a useful lens, and each one brings out structure the lower realm cannot express. By the time we reach the top, one specific shape of AGI becomes very hard to avoid.
金刚境 — The Diamond Realm: A neural network is a PDE solver
Take the simplest possible neural-network claim seriously. Forward propagation is iterated integration; backpropagation is residual correction; activation functions inject high-order nonlinearity. Sum it up and you are looking at a numerical solver for a high-order nonlinear partial differential equation.
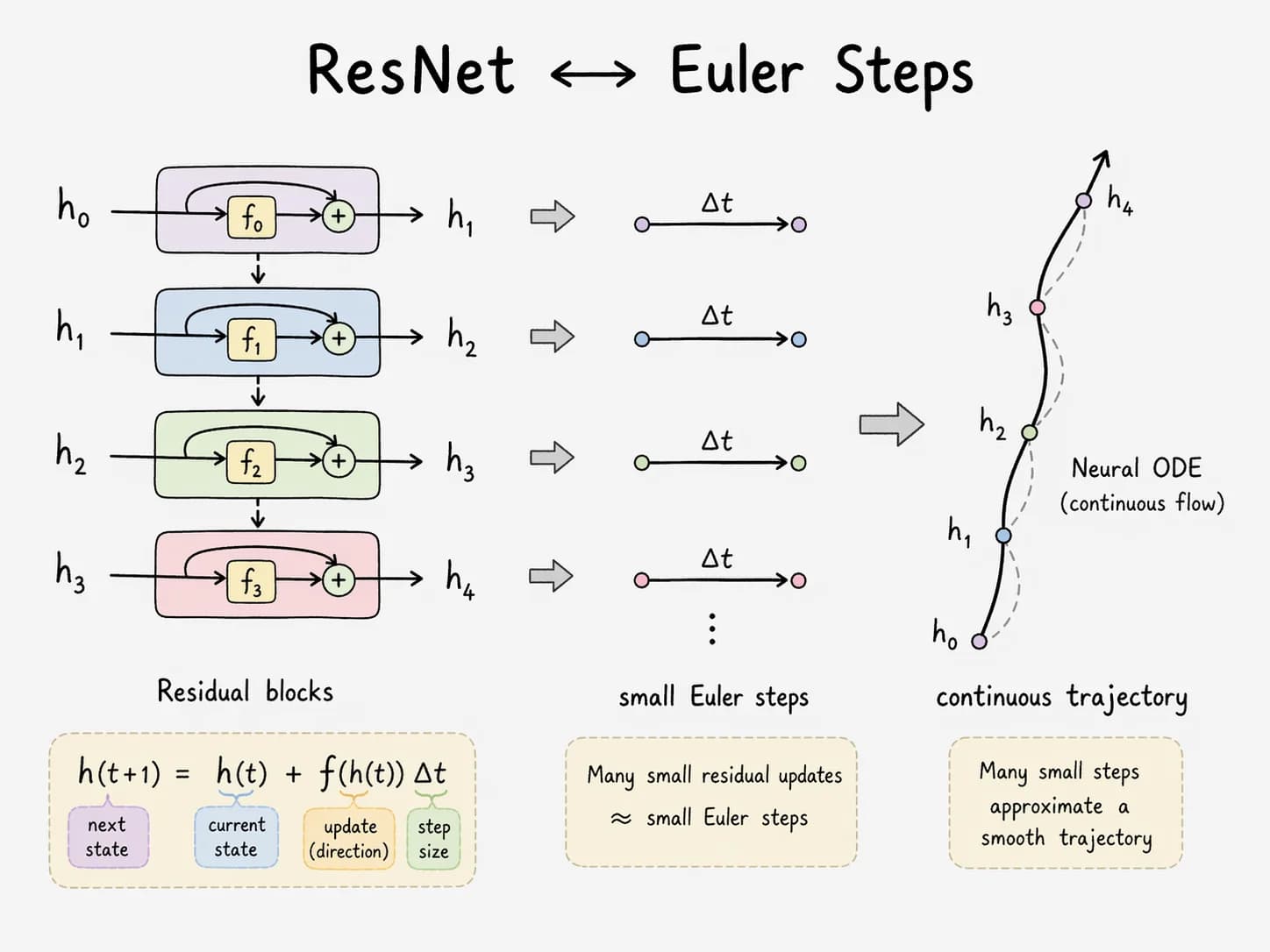
This is not metaphor. A Transformer block — attention plus MLP, each with a residual connection —
is Euler's method for an ordinary differential equation. Chen et al. (2018) made this rigorous for residual networks in Neural Ordinary Differential Equations: replace a discrete residual stack with a continuous adaptive ODE solver and you get a working neural network with constant memory cost. The same residual shape sits inside every Transformer block. Depth becomes integration time.
Backpropagation, for its part, is not a machine-learning invention. It is the adjoint sensitivity method — a 1960s control-theory technique for propagating gradients backward through a dynamical system. Linnainmaa wrote it down in 1970. Werbos applied it to neural nets in 1974. But it was the 1986 Nature paper by Rumelhart, Hinton — my professor at the University of Toronto, and a 2018 Turing Award laureate — and Williams, Learning representations by back-propagating errors, that showed the trick scaled and mattered. Every gradient update in every model shipping today is a direct descendant of those three pages.
Activation functions earn their own sentence. Without them, any stack of linear layers collapses to a single affine map — Cybenko's 1989 universal approximation theorem requires nonlinearity. The sigmoid, tanh, ReLU, GELU you see in code are not aesthetic choices; they are the nonlinear perturbation that prevents a 200-layer network from being algebraically equivalent to a 1-layer one.
This reading is structural — no one has written down the PDE a given Transformer is solving, and there may not be one in closed form. What the view does give you is a one-to-one correspondence of parts: iterated forward steps, adjoint-method gradients, nonlinear coefficients, boundary conditions. Stated cleanly: a Transformer behaves like a PDE whose coefficients are learned by gradient descent, and whose boundary conditions are your prompt.
This is a useful thing to see. It is also the lowest realm, because it tells you what the machine is computing without telling you why the computation works.
指玄境 — The Pointing-Mystery Realm: Training is geometric flattening of a manifold
Fold a sheet of paper into an airplane. Now fold ten sheets each into different airplanes, stack them in the air, and ask: how would you flatten all of them into a single 2D plane such that the original creases still let you tell each airplane apart?
This is what training a neural network does. Each class of input — cats, dogs, the word France — lives on a curved, locally Euclidean submanifold inside the ambient input space. Raw pixels or tokens tangle these manifolds together. Training progressively unfolds them until they are linearly separable.
Christopher Olah's Neural Networks, Manifolds, and Topology (2014) is still the cleanest visualization of this picture. The machinery factors into three elementary moves:
- Linear transform → flatten and rotate. An affine layer reorients the ambient space — rotation, scaling, shear, projection, translation are all on the table.
- Activation → bend. A nonlinearity locally stretches or compresses along each coordinate, putting curvature where there was none.
- MLP dimension shift → cut and re-glue. Changing the hidden dimension is topologically analogous to embedding the manifold in a higher-dimensional ambient space where tangled submanifolds can be pulled apart.
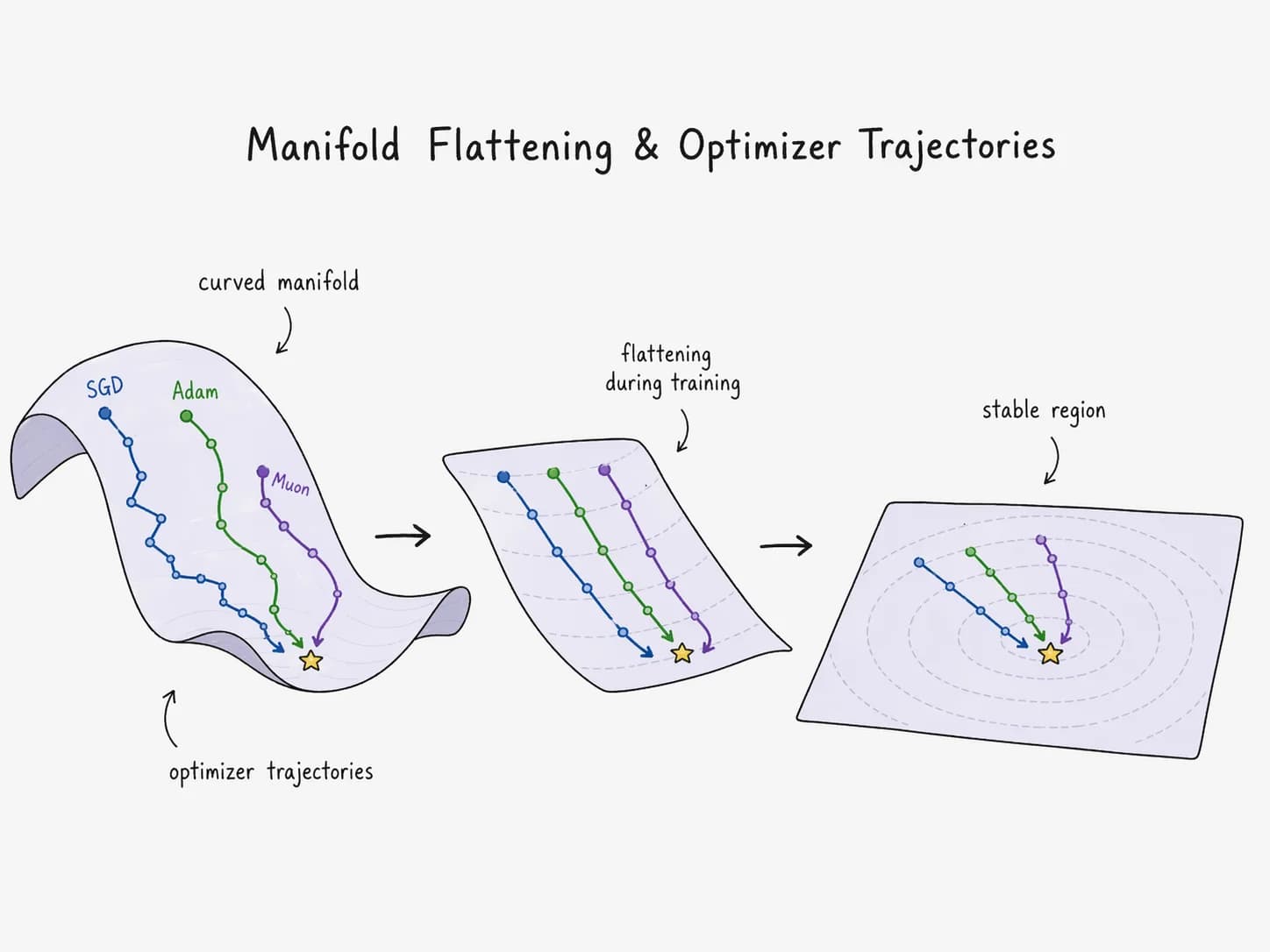
A trained weight matrix, under this reading, is a choreography: where to transform, how hard to bend, and where to translate. The loss landscape has not one optimum but many — N > 1 fixed points that all flatten the manifolds acceptably well. Training is the geometric search for any one of them.
Max Ma X and Gen-Hua Shi's Deep Manifold framework makes this mathematically explicit: neural networks are "learnable numerical computation" over stacks of piecewise-smooth manifolds, grounded in fixed-point theory. The framework's claim — that a neural network is the first computational object whose structure is defined by counting fixed points over nested manifolds — lines up exactly with the geometric picture above. It is the formal statement of what Olah showed visually.
The strongest recent signal that geometry is the right prior comes from optimizers. Muon, introduced by Keller Jordan in late 2024, post-processes each SGD momentum update by running a Newton–Schulz iteration that approximately replaces the update matrix with its nearest semi-orthogonal counterpart — effectively projecting the update onto from the SVD. Orthogonal updates are isometric: they rotate the weight-space tangent vector without rescaling any direction. SGD is axis-aligned. Adam is per-coordinate rescaling that does not preserve the geometric structure the manifold view cares about. Muon treats the weight matrix as what it actually is — a geometric object — and updates it accordingly. On NanoGPT speedruns it wins. The lesson generalizes: the right inductive bias for a 2D weight matrix is a geometric one.
天象境 — The Heavenly-Phenomenon Realm: Weights are a connection on a fiber bundle over the data manifold
The geometric picture is still too flat. Real data is not just a manifold in input space — it is a manifold with structure attached at every point. To see that structure, we need the language of gauge theory and fiber bundles.
Start with a name. Chen Shing-Shen (陈省身, 1911–2004) was a Chinese-American geometer whose work on characteristic classes — the Chern classes, the Chern–Simons form, the Chern–Gauss–Bonnet theorem — underpins essentially all of modern gauge theory and much of string theory. He was Yau Shing-Tung's doctoral advisor. His fiber-bundle machinery is what physicists use to describe every fundamental force we know.
In physics:
- Electromagnetism is a U(1) gauge theory; the gauge field is the electromagnetic potential.
- Weak force is SU(2). Strong force is SU(3). The Standard Model is SU(3) × SU(2) × U(1).
- Gravity curves spacetime — a connection on the tangent bundle of the 4-manifold we live on.
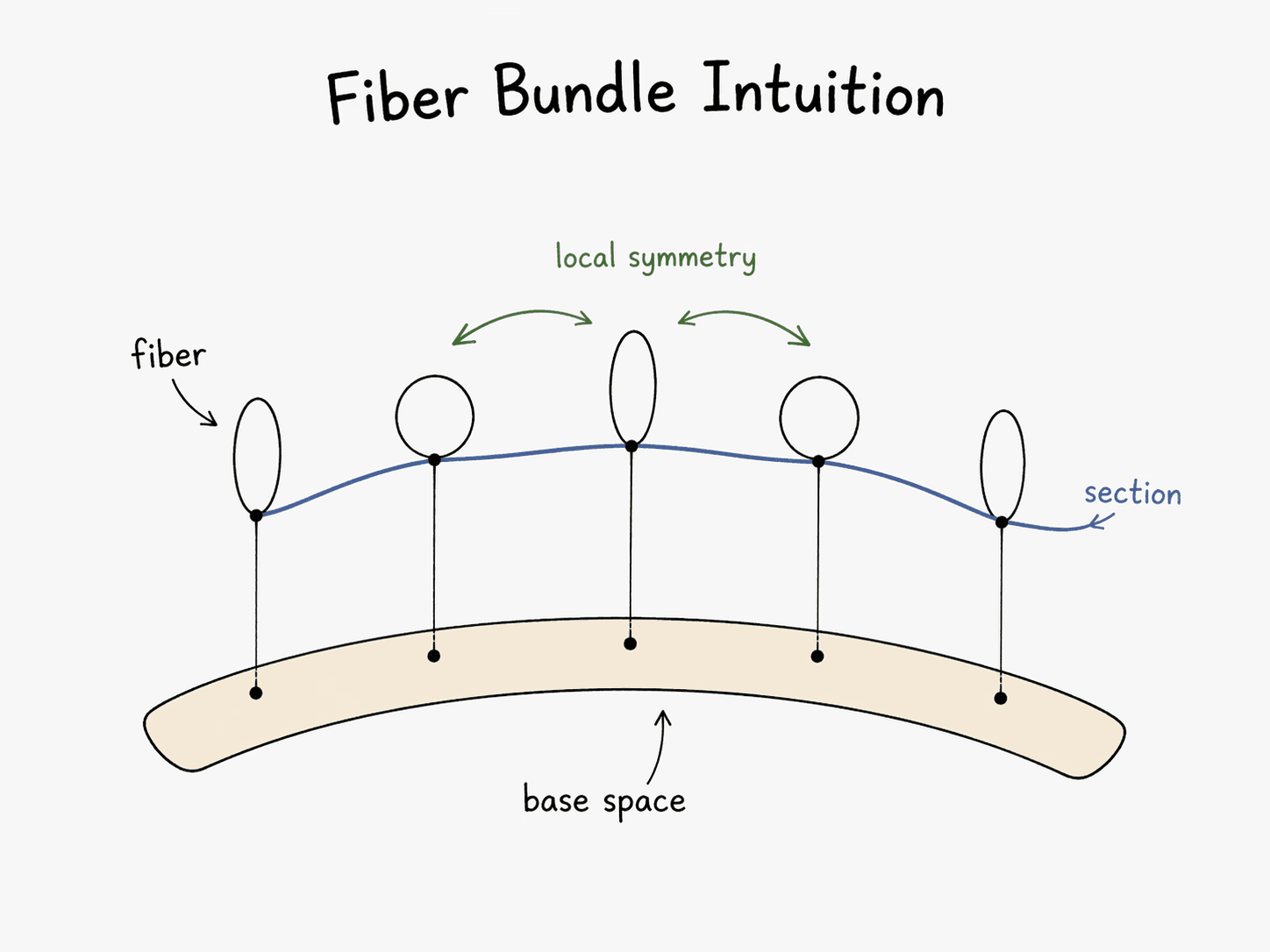
In every case the picture is the same: a base manifold (spacetime, or more generally the configuration space), a fiber attached at every point (internal states — electron phase, quark color), and a connection that tells you how to transport a fiber element from one point to another along a path.
Now map it onto deep learning:
- Base manifold = the data distribution. Your training set samples points from it. Its intrinsic Shannon entropy is an invariant of the distribution, not of any model.
- Fiber = the latent feature space at a data point — the activations at a given layer, given a given input.
- Fiber bundle = the total space of all latent states over all data points. This is the object the network actually models.
- Connection = the weights. Weights specify how a feature vector at one point is transported to a feature vector at a neighboring point. Pre-training is the process of learning a connection.
- Curvature = the extent to which parallel transport around a closed loop fails to return to the identity. In gauge theory this is field strength (Yang–Mills). In a neural network it is what the model has learned beyond the data — the non-local structure that connects far-apart parts of the manifold.
This is not hand-waving. Cohen, Welling, and collaborators built Gauge Equivariant Convolutional Networks (2019) that explicitly implement convolutions as parallel transport on a principal bundle — and they beat standard CNNs on spherical data, where the gauge group U(1) is nontrivial. The broader programme is laid out in Bronstein, Bruna, Cohen, Veličković's Geometric Deep Learning (2021): every useful inductive bias — translation equivariance in CNNs, permutation equivariance in GNNs, rotation equivariance in graph nets — is a symmetry of the fiber bundle. Choose the symmetry group well and you need less data.
The payoff of this realm: you stop thinking of weights as "knobs to tune" and start thinking of them as the connection on the bundle that makes the data manifold locally meaningful.
陆地神仙境 — The Earthbound Immortal Realm: Attention is quantum-like measurement
There is one step further up. Training is classical: given a data distribution, minimize a loss. Every gradient step assumes the world sits still while you measure it. Frequency defines truth.
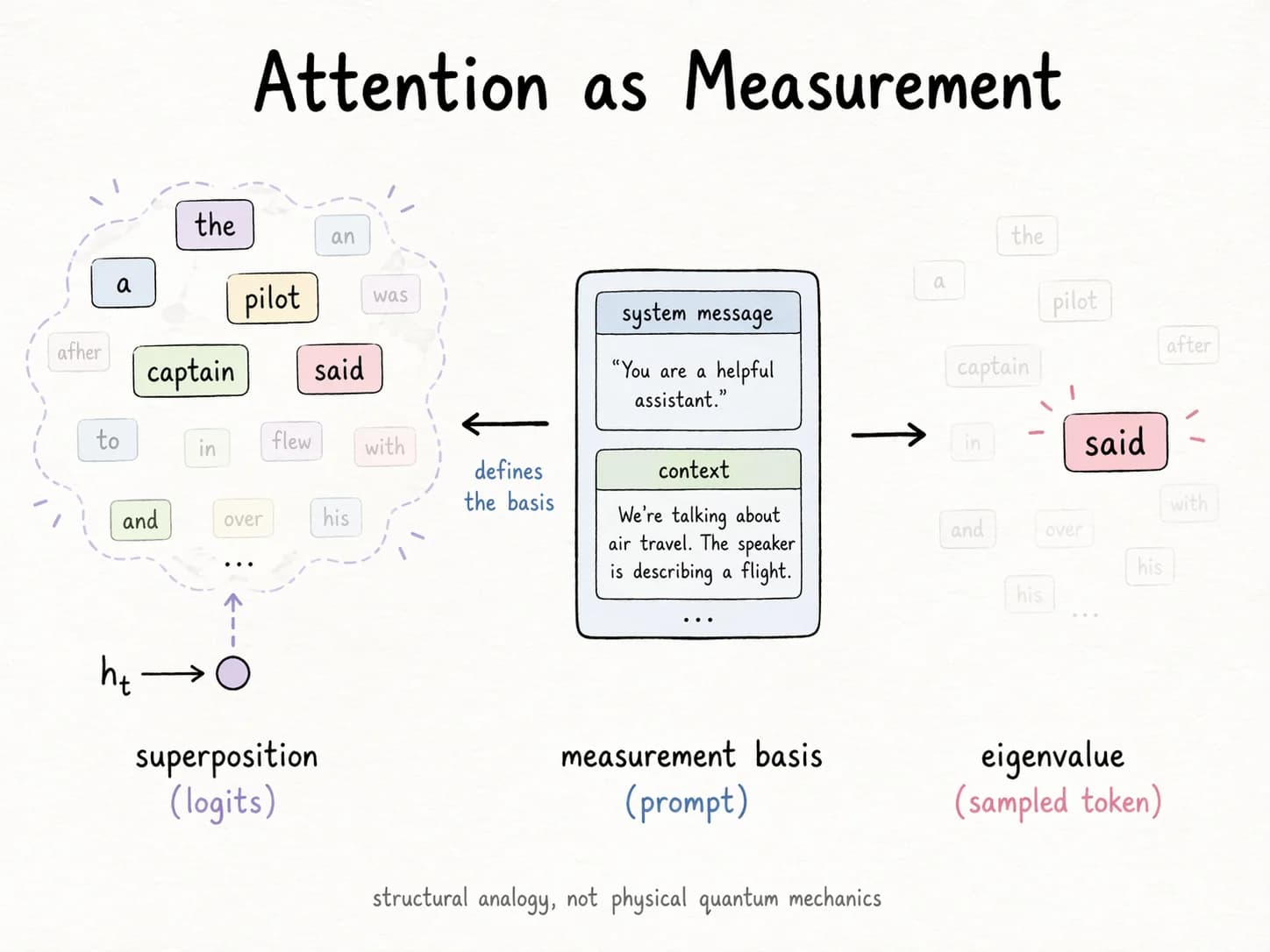
Inference is not like this. At inference time, the model carries a superposition of plausible continuations. The next-token distribution is a cloud over a vocabulary of ~100,000 possibilities. Attention is how the cloud chooses: measures the overlap between what the current position wants and what every earlier position offers, and softmax collapses that overlap into a concrete weighted mixture. The model does not produce a token; it collapses into one when queried.
A concrete instance: feed the prefix "The pilot said" to the same model under two different system messages — one that primes a technical audience, one that primes a bedtime story for a child. The next-token distribution is different in each case. The prefix didn't change. What changed was the measurement basis.
This has the structure of quantum measurement. The training distribution is the prior. The prompt is the apparatus — it selects the basis. The generated token is the eigenvalue you read off. Busemeyer and Pothos' quantum cognition programme has argued for over a decade that human decision-making shows the same formal structure, down to violating classical probability axioms in predictable ways.
To be explicit: I mean this as a structural analogy, not a physical claim. No superposition is collapsing; no Planck constant is involved. What is happening is that the same formal machinery — a possibility distribution, a basis-dependent projection, an irreversible readout — shows up in all three domains, and that is enough to make the comparison load-bearing rather than decorative.
Humans agree. Memory, as Karim Nader's work on reconsolidation (2000) showed, is not stable storage; it is re-formed every time you retrieve it, using the context at the moment of retrieval. The act of recall is the act of creation. Sleep — specifically slow-wave sleep, per Tononi and Cirelli's synaptic homeostasis hypothesis — then renormalizes synaptic strengths downward, compressing and forgetting to free capacity for tomorrow.
Three domains — quantum physics, cognitive psychology, deep learning — give the same pattern: reality is not a pre-stored tensor. It is the collapse of a possibility cloud into a measured value at the moment of contact.
And here is what that forces.
So what does AGI have to look like?
Take the four realms together. An AGI that respects all of them is not a single giant model serving every query. It is something much stranger, and much smaller per user.
Consider the failure modes of a modern LLM in this frame.
Redundant concept encoding. In a two-trillion-parameter model, France and 法国 map to different input embeddings, and the same France token in different contexts produces different contextual activations at every layer. In a human brain, all of these point at the same concept node, reached by different retrieval paths. Anthropic's Scaling Monosemanticity (2024) work on sparse autoencoders shows that Claude has partially discovered this — many learned features are language-agnostic concepts. But the computation still routes through token-level embeddings and rediscovers the concept every pass. Geometrically, this is waste.
Circuit reuse. A human who has learned the concept uncle can apply it to any new family zero-shot. An LLM needs many in-distribution examples to reliably compose "mother's brother" into the uncle relation on new symbols. The same relational circuit should be reused. This is the compositional generalization problem — Lake and Baroni's SCAN (2018) formalized this failure mode for standard seq2seq models; Anthropic's induction heads and Pedro Domingos' Tensor Logic both point at the fix.
Personal dynamic memory. Every person you know reminds you of different things. "A works at Google" triggers Silicon Valley for one reader, six-figure salary for another, my cousin's job for a third. The associative circuit is per-person, updated every waking hour, compacted every sleep cycle. A single static model cannot represent this. A per-user memory surface can.
Put the three together and the engineering picture is sharp:
- One small core reasoning model — the "nine-year compulsory education" base: trained on clean, deduplicated, concept-level data.
- Modular specialist regions — visual, motor, linguistic, social — analogous to cortical areas.
- A single dynamic memory layer per user — updated from lived interaction, compacted during idle time, never shared.
- Unified substrate. Concept vectors × logic tensors as the basic operation. Chained logic is continuous multiplication. Long-range reasoning is differentiable nested equations. Perception is the particle-to-concept grounding process. Population behavior is entropy statistics. Individual behavior is quantum — a trajectory of measurements made by this person.
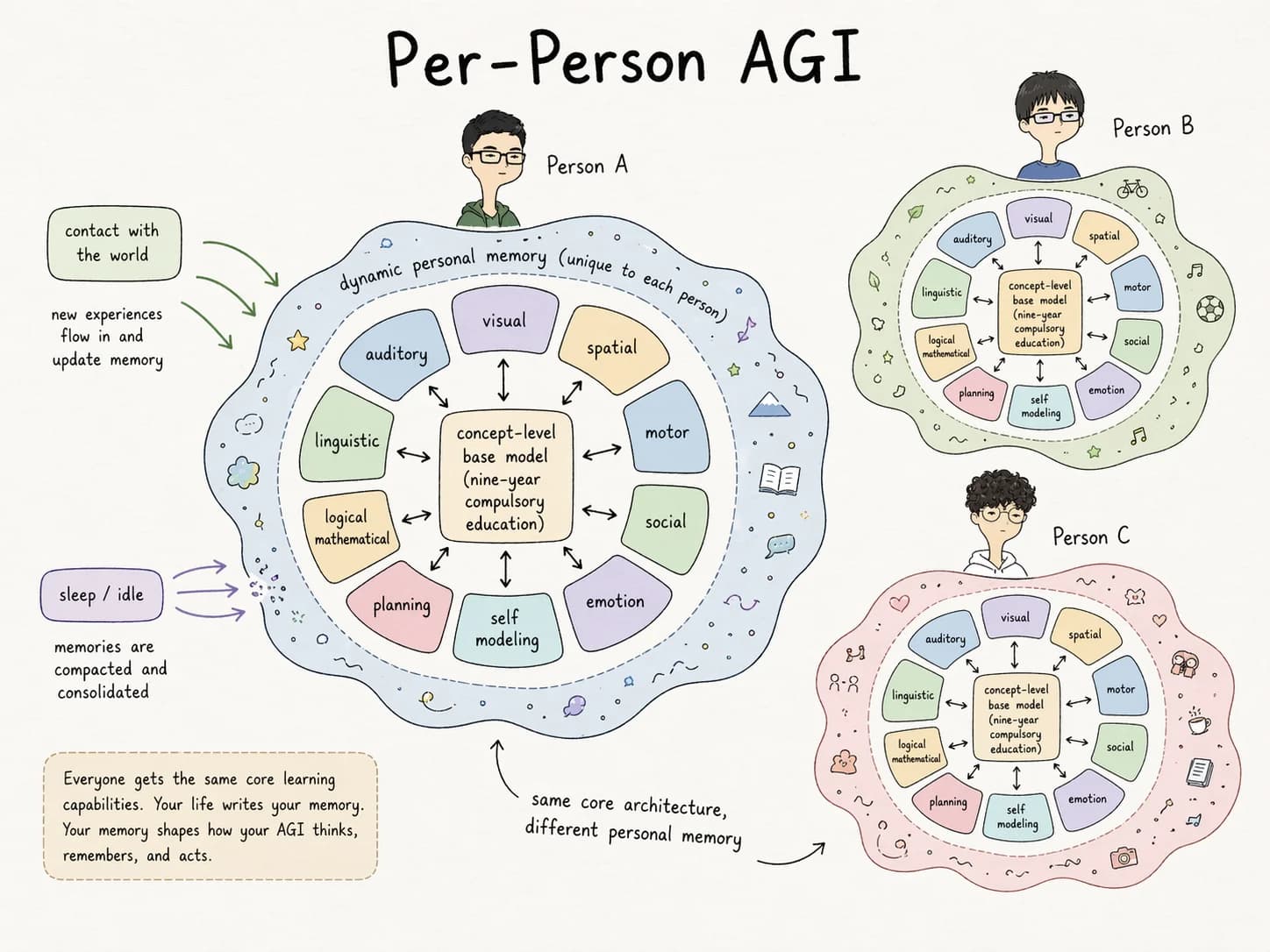
This is the shape my own Tensor Logic work aims at. Small core. Dynamic per-user memory. Modular composition.
The thesis
AGI will not be one model for everyone. It will be one model per person — modular, dynamic, small enough to run locally, and trained on the contact surface between that person and the world.
The four realms tell you why:
- The PDE realm says the computation is numerical. With enough silicon it can be run anywhere.
- The manifold realm says what matters is geometry, not parameter count. Orthogonal updates on a small matrix can beat sloppy updates on a huge one.
- The gauge field realm says the weights are the connection on the data bundle. Different people live on different manifolds; their connections should differ.
- The quantum attention realm says the answer does not exist until it is asked for. Personal context is the measurement apparatus. There is no universal answer to collapse.
One model, many users, one answer is the wrong fixed point. The right one is the per-person attractor that only forms under contact.
That is the earthbound-immortal realm. Everything below it is a stepping stone.