This post is a rewrite of my original piece from 2025-03-27, which accompanied a Bilibili video on the same topic.
Everything a large language model does — predicting the next token, learning from data, compressing knowledge into weights — traces back to a paper Claude Shannon published in 1948.
This is not a metaphor. The math is literally the same.
Information Content and Entropy
Shannon's core insight: the information content of an event is inversely related to its probability.
A fair coin landing heads gives you 1 bit of information. A die landing on 6 gives you ~2.58 bits. Winning the lottery? About 23 bits. The rarer the event, the more you learn when it happens.
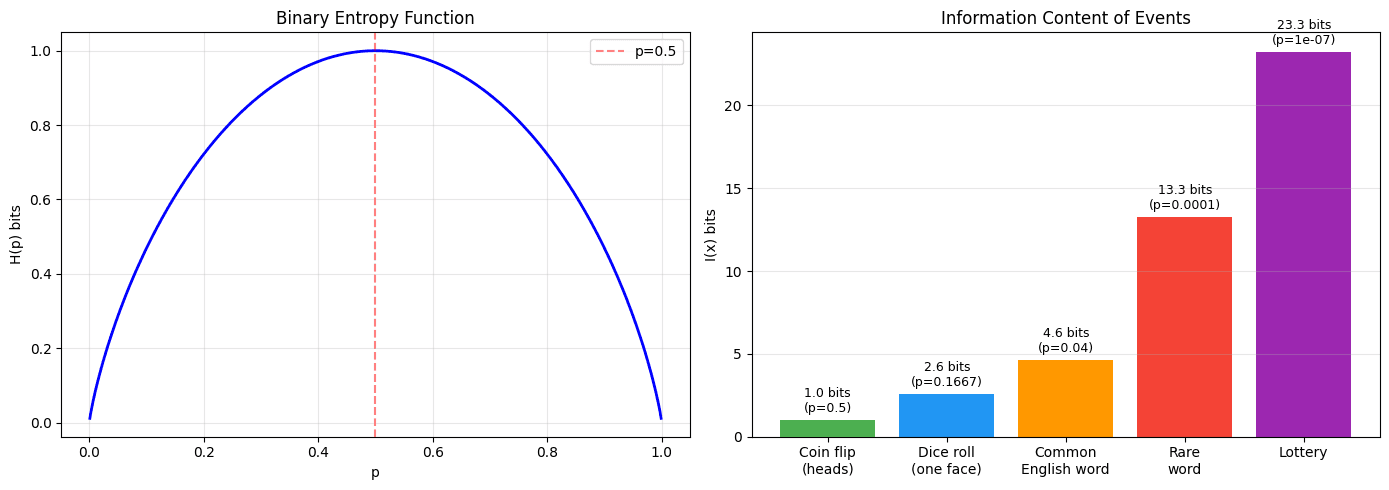
Entropy is the expected information content across all possible outcomes:
This single formula defines the theoretical limit of lossless compression, the minimum average bits needed to encode a message, and — as it turns out — the training objective for every modern language model.
Why LLMs Use Cross-Entropy Loss
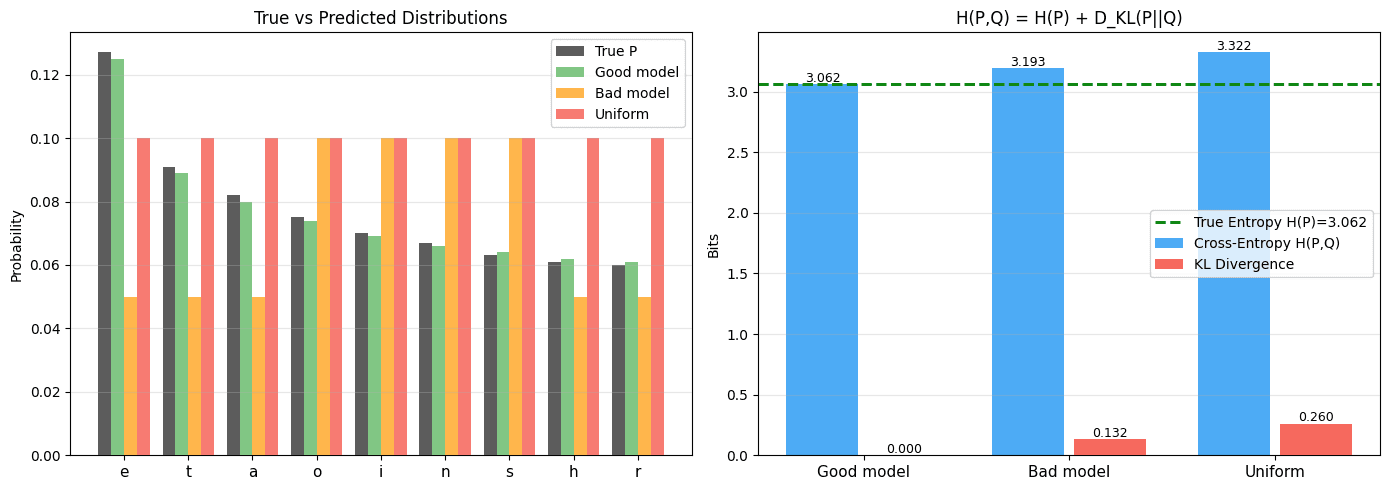
When we train an LLM, we minimize the cross-entropy between the true next-token distribution and the model's predicted distribution :
Cross-entropy decomposes cleanly:
The true entropy is fixed — it's a property of the language itself. So minimizing cross-entropy is equivalent to minimizing KL divergence, which means pushing the model's predictions as close as possible to the true distribution.
This is not a design choice someone made arbitrarily. It falls directly out of information theory.
Attention as Mutual Information
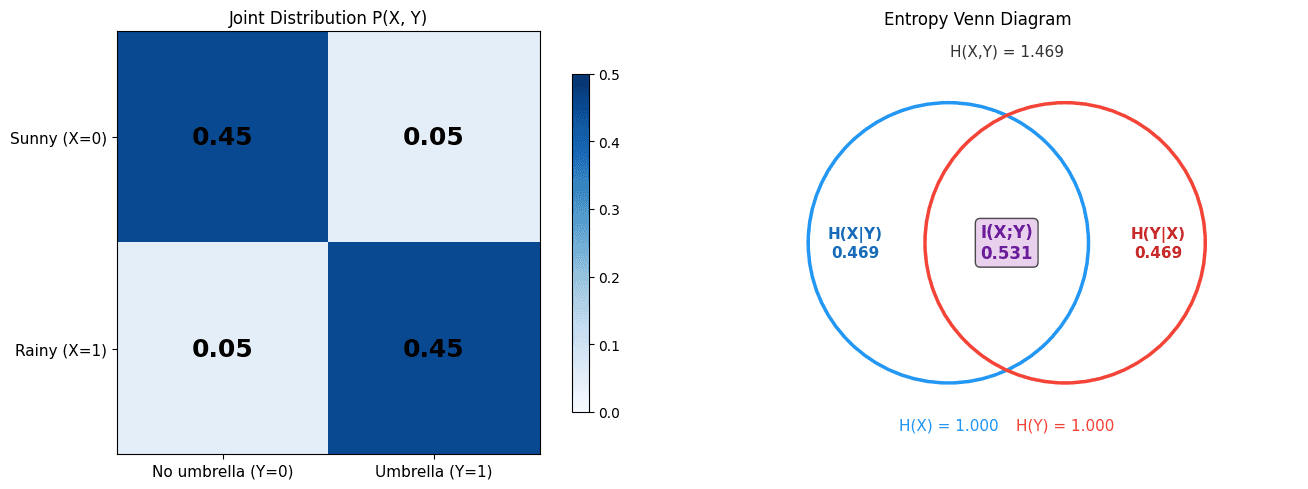
Mutual information between two variables and measures how much knowing one reduces uncertainty about the other:
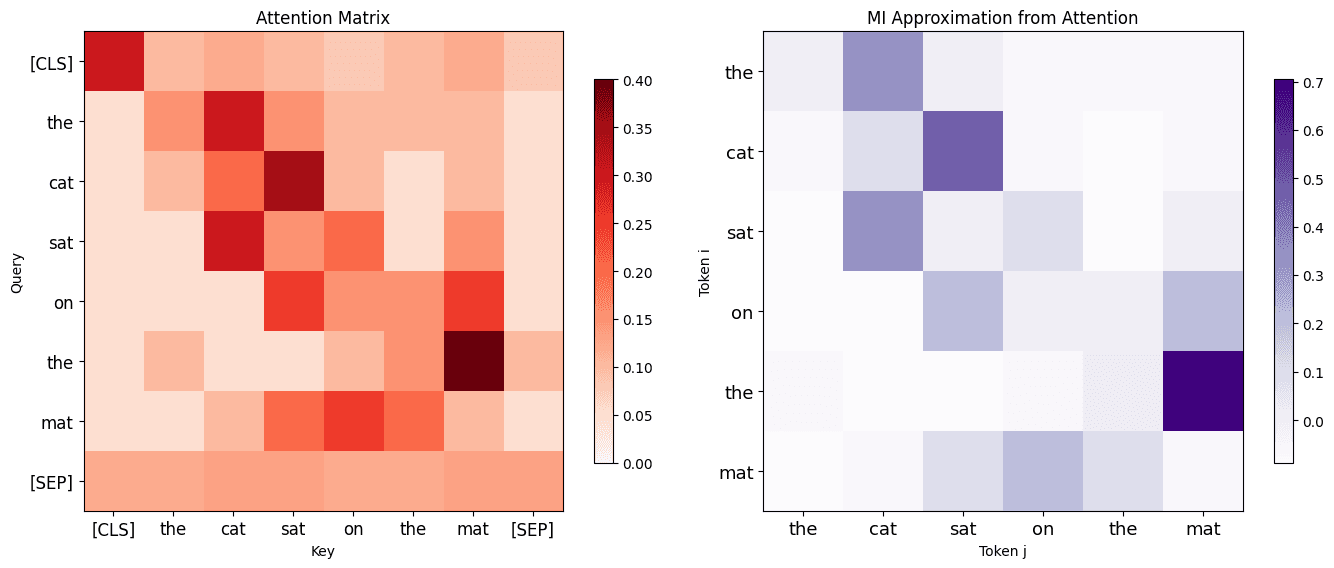
Self-attention does something analogous. The dot product quantifies how much each token's representation depends on every other token. The attention weights after softmax approximate a conditional distribution — how much information token provides about token .
The attention mechanism is not computing mutual information in the strict mathematical sense. But it is parameterizing the same dependency structure that mutual information describes, and the training objective (cross-entropy) ensures the model learns the real dependencies in the data.
The Thermodynamic Bound
Here is the part most people miss: no model architecture can extract more information from a dataset than the dataset contains.
This is not a conjecture. It follows from the same principles that give us Landauer's limit in physics — erasing 1 bit of information requires a minimum energy expenditure of .
For a fixed training set, it does not matter whether you use a Transformer, Mamba, RWKV, or any future architecture. You can optimize extraction efficiency (LoRA is efficient, full fine-tuning is expensive), but you cannot create information that is not there. The training data is the ceiling.
This is why data quality matters more than model size past a certain scale, and why synthetic data generation has a fundamental bootstrap problem.
Compression Is Intelligence
Shannon entropy defines the optimal compression limit. A string of "aaaa" repeated 1000 times has near-zero entropy — it compresses to almost nothing. Random bytes have maximum entropy — they cannot be compressed at all.
Language sits between these extremes. It has structure, patterns, and redundancy. A language model that predicts well is, by definition, a good compressor — and vice versa.
This is not just an analogy. The Hutter Prize, one of the oldest benchmarks in AI, literally awards money for the best compression of Wikipedia. And the best compressors are always language models.
V-Information: When Computation Matters
Classical Shannon theory assumes unlimited computational resources. V-information theory extends this by asking: how much information can be extracted by a specific class of models with bounded computation?
This reframes the question from "how much information is in the data?" to "how much information can this model actually use?" It explains why self-attention extracts more useful information than, say, a bag-of-words model from the same data — not because the data changed, but because the extraction method is more powerful.
V-information is still more heuristic than operational, but it provides the right framework for thinking about why some architectures learn faster than others.
Interactive Notebook
I put together a Jupyter notebook that walks through all of this with interactive code — entropy curves, mutual information Venn diagrams, cross-entropy vs. KL divergence visualizations, attention heatmaps, and compression experiments.
Available in both Chinese and English:
Interactive tutorial: Information Theory and LLM Language Modeling
The notebook is meant to be run, not just read. The visualizations make these concepts click in a way that equations alone cannot.